PM:Assembler Tutorial
aus PortableDev, der freien Wissensdatenbank
| Inhaltsverzeichnis |
Pokémon Mini Assembler
Was ist Pokémon Mini?
Der Pokémon Mini ist eine Mini-Konsole, die für wenig Geld viel bietet. Der enthaltene Prozessor scheint eine Eigenproduktion von Nintendo zu sein und ist daher noch nicht vollständig "geknackt". Mit dem was man jetzt schon über PM weiss, lässt sich eine Menge anstellen. Er hat ein monochromes Display (schwarz/weiß über sogenanntes Flickering auch grau) das 96 * 64 Pixel groß ist. Ebenfalls besitzt er 2 Timer jeweils mit einer Taktfrequenz von 1 Hz und 256 Hz. Zu den Highlights des kleinen Meisterwerks gehören IR-Schnittstelle, Rumblemotor sowie Shocksensor. Auch für eine integrierte Uhr haben die Hersteller gesorgt.
Technische Daten:
CPU 4 MHz BIOS 4 KBytes RAM 4 KBytes Video 96 * 64 Monochrome LCD Display, Hardware Tiles und Sprites, Hardware Kontrasteinstellung Sound 1 x Channel Generator Timer 1 x 24 Bit Sekundenzähler 1 x 8 Bit 256 Hz Zähler Extras 1 x Rumblemotor 1 x Shocksensor 6 x Slots SaveGame RAM 1 x RTC Uhr 1 x IR-Schnittstelle Verosrgung 1 x AAA 1,5 Batterie Displayrefreshrate 60 Hz
Was ist Assembler?
Jede ausführbare Datei die Sie aufm Ihrem Rechner haben, liegt im sogenannten Maschinencode vor. Bei jedem ausführen dieser Datei wird sie in den Arbeitspeicher geladen, und die CPU(Central Processing Unit – Zentrale Recheneinheit) übersetzt das Programm Stück für Stück. Jede CPU bringt dafür einen eigenen Befehlssatz mit. Jetzt dürfen Sie sich ein Befehl nicht vorstellen wie „Verbinde mich mit Internet“, sondern eher wie „Kopiere Speicher von Stelle A nach Stelle B“. Ein Programm ist somit doch komplexer als man manchmal denkt. Ein Maschinencode ist eine Abfolge von lauter Nullen und Einsen(das Lochkartenprinzip). Um das ganze übersichtlicher zu halten, benutzt man Assembler. Diese wandeln sogenannte Mnemonics wieder in Nullen und Einsen um. Mnemonics sind einfach gehaltene Wörter, besser gesagt Abkürzungen die den jeweiligen Maschinenbefehl aus Nullen und Einsen repräsentieren. Nehmen wir den wohl bekanntesten Mnemonic MOV a, b. Er kopiert den Inhalt von Register B(Register sind Speicherstellen in der CPU selber) in Register A. MOV lässt sich ableiten vom englischen Wort Move – Bewegen. Der Assembler wandelt ihn in 00101000 00000001b um. Wie Sie sehen, ist das Verwenden von MOV a, b bequemer als selber Nullen und Einsen einzutippen. Da Mnemonics immer englischen Ursprungs sind besser gesagt alles was mit Programmieren zu tun hat englisch ist, sind Englischkenntnisse dringend erforderlich. Weiter ist es nützlich in einer Hochsprache z.B. in BASIC programmieren zu können, da man sich hier nützliche Werkzeuge schreiben kann.
Welche Ausrüstung brauche ich?
Wichtig wäre ein Assembler der Mnemonics in Maschinencode umwandelt und ein Emulator der den PM am PC simulieren kann. Bei Programmieren ist ein Debugger recht hilfreich. Hier kann man sein Programm gezielt Schritt für Schritt ausführen lassen, und schauen was passiert. Sehr nützlich wenn man nach Fehlern im Programm sucht. Ohne Hardwaredokumentation können wir natürlich nicht programmieren. Sie ist essentiell(lebensnotwendig) für uns. In ihr ist aufgeführt, wo wir unser Logo kopieren müssen, damit es auch auf dem PM zu sehen ist, wie ich einzelne Tasten abfragen kann u.s.w. Weiter gibt es ganz nützliche Tools die z. B. BMP Bilder in binärer Form umwandeln, damit wir sie einfacher in unsere Programme einbinden können.
Assembler http://pokeme.guruwork.de/infos/(Dis)Assemblers/pmas.zip Open Source Assembler inklusive DisAssembler(wandelt Maschinencode in Assembler um)
Emulator http://pokeme.guruwork.de/infos/Emulators/PokeMini_0-28.zip Grafisch sehr gut. Kann auch event. Sound emulieren.
Debugger http://pokeme.guruwork.de/infos/Debuggers/PokeKaMini_0-6-3F2.zip Unterstützt Watch und Breakpoints sowie Singlesteps. Mnemonics können direkt im Debugger verändert werden.
Dokumentation http://pokeme.guruwork.de/?button=infos Sehr wichtig wären hier pokemonhw.htm, io.txt und mindx13_DF.txt.
Tools http://pokeme.guruwork.de/infos/Graphics%20Tools/bmp2bin.zip Wandelt BMP Bilder in binäre Dateien um, zum Einbinden in Programme.
Wir schreiben unser erstes Programm
Es ist Tradition in jeder Programmiersprache ein "Hello World" auszugeben. In Assembler gestaltet sich das oft schwieriger als in BASIC, das mit einem einfachen Print "Hello World!" getan ist. Deswegen wollen wir uns drauf beschränken, eine simple Addition von 1 + 2 zu realisieren. Für unser erstes Programm legen wir einen Ordner namens "Pokémon Mini Dev" z.B. In C:\Eigene Dateien an. Er ist folgendermaßen strukturiert:
+ Pokémon Mini Dev + Projects + Assembler + Emulator + Debugger + Tools
Im Ordner Projects legen wir einen Unterordner genannt “Addition” an. In Assembler kommt unser pmas Assembler, in Emulator unser PokeMini Emulator, in Debugger unser PokeKaMini Debugger und in Tools unser bmp2bin Konverter hinein. Die Struktur sollte nun so aussehen:
+ Pokémon Mini Dev + Projects + Addition + Assembler + Src - mindx.txt - pmas.exe - pmdis.exe - readme.S - wordfile.txt + Emulator - PokeKaMini_Debug.exe + Debugger - PokeMiniEmu.exe + Tools - bmp2bin.cpp - bmp2bin.exe - gpstd.act - grayscale.act - pm.act
Weiter brauchen wir im Ordner Addition folgende Dateien:
- Addition.asm – unser Programmcode - Make.bat – mit ihr erstellen wir ein ausführbares Programm
Addition.asm beinhaltet folgenden Quellcode:
.orgfill 0x0009A jmp main .orgfill 0x02100 .db "MN" .orgfill 0x021A4 .db "NINTENDO" .db "XXXX" .db "Addition" .orgfill 0x021BC .db "2P" .orgfill 0x021D0 main: movb a, 1 ; kopiere 1 in Register A addb a, 2 ; addiere 2 hinzu end: jmp end
und Make.bat sieht folgendermaßen aus:
..\..\Assembler\pmas.exe Addition.asm Addition.min @Echo Fertig
Starten wir nun Make.bat. Wenn alles gut gelaufen ist, sollten wir folgenden Bildschirm vorfinden:
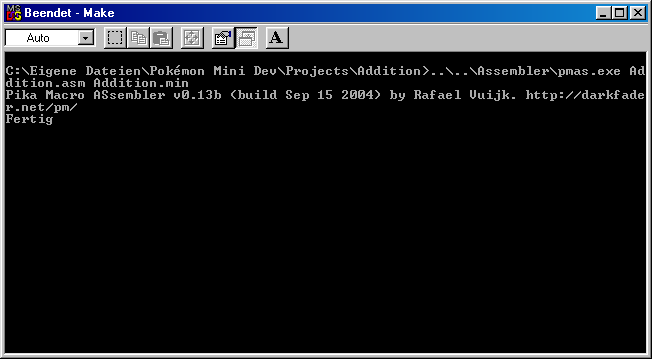
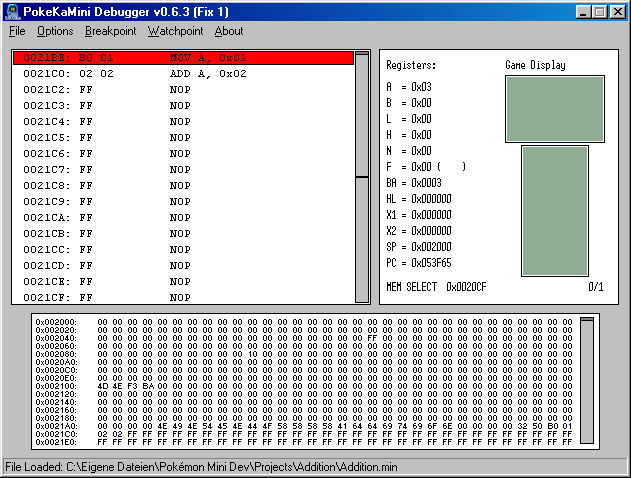
Wenn wir jetzt unser Programm im Emulator aufrufen, werden wir nix großartiges sehen können. Deswegen benutzen wir unseren Debugger, der auch den Status einzelner Register(wird später erklärt) anzeigen kann. Also starten wir PokeKaMini_Debug.exe und wählen im Menü File -> Open .Min aus. Hier müssen wir unsere kompilierte Addition.min angeben. Jetzt können wir unser Programm mit [F5] starten. Das Resultat ist, dass nun in Register A 0x03 steht. Also 1 + 2.
Zahlensysteme
Das wohl bekannteste Zahlensystem ist das arabische Zahlensystem das auch wir benutzen also 0, 1, 2 etc. sowie das römische I, II, III, IV, etc. Jetzt fragen Sie sich sicherlich was das ganze mit Assembler zu tun hat. Nun in der Digital- und Programmierwelt haben sich zudem das Binär- und Hexadezimalsystem etabliert.
Das Dezimalsystem
Das System das auch wir verwenden um z.B. den Preis eines Apfels anzugeben heißt Dezimalsystem. Dezimal steht für Zehn. Es entwickelte sich aus der Tatsache heraus, das man mit 10 Fingern recht gut rechnen kann. Als Beispiel nehmen wir 123,45 in Langschreibweise ist die Zahl so aufgebaut:
1 * 10^2 + 2 * 10^1 + 3 * 10^0 + 4 * 10^-1 + 5 * 10^-2
Man erkennt deutlich das alles auf der Zahl 10 basiert. Die Nennwerte - die ganzen Zeichen die ein Zahlensystem beinhaltet, wären {0, 1, 2, 3, 4, 5, 6, 7, 8, 9}. Die Anzahl der Nennwerte wären hier 10. Damit lässt sich jede(bis auf die nicht rationalen) Zahl darstellen.
Das Binärsystem
Das Binär- oder auch Dualsystem genannt besitzt als Basis die 2. Bi oder Dual steht immer für 2. Die Nennwerte des Binärsystems sind {0, 1}. In Zusammenhang mit dem Binärsystem steht das Bit – die kleinste Speichereinheit im Computer. Bit steht für binary digit also binäre Zahl. Mit der Anzahl an zu Verfügung stehenden Bits wächst auch die Anzahl an Kombinationsmöglichkeiten.
Bei 2 Bit wären es:
Kombination 1: 00 Kombination 2: 01 Kombination 3: 10 Kombination 4: 11
Bei 3 Bit:
Kombination 1: 000 Kombination 2: 001 Kombination 3: 010 Kombination 4: 011 Kombination 5: 100 Kombination 6: 101 Kombination 7: 110 Kombination 8: 111
Daraus ergibt sich folgende Formel: 2^n = Anzahl der Kombinationsmöglichkeiten. Ein Byte besteht aus 8 Bit. Somit kann es 2^8 = 256 verschiedene Zustände speichern. Diese gehen von 0 bis 255.
Hexadezimalsystem
Aus der Tatsache heraus, das ein Nibble oder auch Tetrade genannt aus 4 Bit besteht und dies 16 Kombinationsmöglichkeiten zulässt, entstand das Hexadezimalsystem. Dezimal steht für 10 und Hexa für 6. 10 + 6 = 2^4 = 16. Bloß wie will man die 16 Zustände veranschaulichen? Mit den Nennwerten 0, 1, 2, 3, 4 ... 12, 13, 14, 15? Wohl kaum. Haben wir die Hexadezimalzahl 1234, kann man nicht unterscheiden, ob mit 12 der Nennwert 12 oder die Nennwerte 1 und 2 gemeint sind. Deswegen nimmt man für 10 bis 15 die Buchstaben A bis F. Die Nennwerte 0 bis 9 bleiben wie gehabt, da man sie von den Buchstaben unterscheiden kann.
Vom Dezimal- ins Binärsystem:
Beispiel 25d:
25 / 2 = 12 Rest 1 12 / 2 = 6 Rest 0 6 / 2 = 3 Rest 0 3 / 2 = 1 Rest 1 1 / 2 = 0 Rest 1
Die Leserichtung ist von unten nach oben also 11001b. Informatiker rechnen natürlich so etwas im Kopf. Man sollte deswegen zumindest die 2er Potenzen von 0 bis 10 auswendig wissen. Diese wären 1, 2, 4, 8, 16, 32, 64, 128, 256, 512, 1024. Jetzt schaut man, welche die größte 2er Potenz ist, die noch in die 25 passt. Dies wäre die 16 also 2^4. Jetzt sieht man schon, dass die binäre Zahl 4 stellen besitzt. Merken wir uns also 1000b. Von der 16 bis zur 25 sind es 9. In die 9 passt die 2er Potenz 8 also 2^3 hinein. Merken wir uns also 11000b. Von der 8 bis zur 9 sind es 1. In die 1 passt die 2er Potenz 2^0. Die 2er Potenzen 2^2 und 2^1 benötigten wir ja nicht, deswegen werden ihre entsprechenden Bits auf 0 gesetzt. Unser Ergebnis lautet 11001b. Dies sollte man mit einem Zettel und Stift auch mit anderen Werten einmal ausprobieren, denn das sollte jeder Informatiker beherrschen.
Vom Binär- ins Dezimalsystem
Beispiel 00111011b
0 * 2^7 = 0 * 128 = 0 + 0 * 2^6 = 0 * 64 = 0 + 1 * 2^5 = 1 * 32 = 32 + 1 * 2^4 = 1 * 16 = 16 + 1 * 2^3 = 1 * 8 = 8 + 0 * 2^2 = 0 * 4 = 0 + 1 * 2^1 = 1 * 2 = 2 + 1 * 2^0 = 1 * 1 = 1
32 + 16 +8 + 2 + 1 = 59d. Auch hier gibt es wieder ein kleinen Trick für das Kopfrechnen. Hat man z. B. die Zahl 1111101111b, addiert man nicht alle 2er Potenzen zusammen, sondern setzt für die 0 erst einmal eine 1 ein - 1111111111b. Jetzt zählt man, wie viel Stellen die Zahl besitzt. In dem Fall 10. Der Nachfolger von 1111111111b ist 10000000000b also 2^10 = 1024d somit ist 1111111111b =1023d. Von der 1023 ziehen wir nun noch 10000b ab, da die 0 an 5ter Stelle war. 10000b ist 2^4 = 16d. 1023 – 16 = 1007d. Das geht auch mit mehreren Nullen, macht aber nur das Sinn, wenn die Einsen überwiegen.
Vom Dezimal- ins Hexadezimalsystem
Beispiel 1234d
1234 / 16 = 77 Rest 2 77 / 16 = 4 Rest 13 = D 4 / 16 = 0 Rest 4
Leserichtung ist wieder von unten nach oben also 4D3h. Auch hier kann man im Kopf mit einer 16er Potenztabelle arbeiten, ist aber nicht mehr so leicht wie im Binärsystem.
Vom Hexadezimal- ins Dezimalsystem
Beispiel 1EFh
1 * 16^2 = 1 * 256 = 256 + 14 * 16^1 = 14 * 16 = 224 + 15 * 16^0 = 15 * 1 = 15
256 + 224 + 15 = 495d. Wie beim Binärsystem.
Vom Binär- ins Hexadezimalsystem
Beispiel 0100 1110b
0100b = 4 1110b = 14 = E
Man unterteilt, wie man erkennen kann, die binäre Zahl in 2 Tetraden auf. Diese Tetraden wandelt man dann in das Hexadezimalsystem um. Somit wäre unser Beispiel 4Eh.
Vom Hexadezimal- ins Binärsystem
Beispiel 5FDh
5h = 0101b Fh = 1111b Dh = 1101b
Hier macht man es genau umgedreht. 5FG werden in jeweils 3 binäre Tetraden umgewandelt. Das Ergebnis ist 0101 1111 1101b.
Puhh, ich hoffe, ich habe hiermit keinen gleich zu Anfang verschreckt. Eine gute Hilfe bietet übrigens der Windows Taschenrechner unter Programme\Zubehör. Schaltet man ihn im wissenschaftlichen Modus, kann man zwischen Hexadezimal-, Binär- und Dezimalsystem wählen. Er wandelt die Zahl in das gewählte Format um. Zusätzlich bietet er das Octalsystem. Hier wird die Basis 8 also Octal verwendet, dieses findet jedoch heute keine Verwendung mehr.
Register des Pokémon Mini
Was sind Register? Nun, es sind Speicherbereiche die fest vertratet mit dem Prozessor sind. Jetzt wird sich sicherlich der ein oder andere Fragen, warum der Prozessor Speicher benötigt, wo es doch ausreichend Speicher im RAM gibt. Aufgrund das Register mit dem Prozessor fest vertratet sind, sind sie wesentlich schneller anzusteuern. Weiterhin werden Register benötigt, um Speicherzellen im RAM anzusteuern, und auch jede Rechenoperation wird mit Registern durchgeführt.
Welche Register gibt es?
8 Bit: A, B, H, L, FLAGS, N, U, V 16 Bit: BA 24 Bit: HL, X1, X2, NN, SP
A, B, H, L können frei verwendet werden. Zu beachten ist, dass sich der 16 Bit Register BA aus Register B und A ergibt. Verändert man B verändert man auch BA. Das selbe gilt für HL und H und L. Im Register FLAGS wird z. B, gespeichert, ob es bei der Addition 2er Zahlen zu einem sogenannten Überlauf(Overflow) gekommen ist. Das bedeutet, wenn eine Zahl nicht mehr in einen Register passt. FLAGS wird häufig auch als Statusregister bezeichnet. Auf die einzelnen Flags selber kommen wir später zu sprechen. N wird häufig als Basis für Speicheradressen verwendet. Hat man z. B. die Adresse 0x002081 und 0x002082(0x kennzeichnet übrigens eine Hexadezimalzahl) speichert man 0x20 in Register N, und kann dann über [NN+0x81] bzw. [NN+0x82] bequem auf die beiden Adressen zugreifen. HL, X1 und X2 werden häufig dazu genutzt, um Adressen abzuspeichern. Der PM ist von 0x000000 bis 0xFFFFFF adressierbar. 0xFFFFFF nimmt 3 Byte -> 24 Bit ein, deswegen sind diese Register ideal zur Adressierung geeignet. NN ist ein Spezialfall. Steht in N 0x20 ist in NN nicht wie zu erwarten 0x2020 sondern 0x2000 enthalten. SP steht für Stack Pointer. Auf den Stack werden wir später noch zurückkommen.
Wenn man jetzt mit Registern programmiert, sollte man immer die kleinstmögliche Größe benutzen. Es wäre sinnlos das Alter einer Person in einem 24 Bit Register abzulegen, ein 8 Bit Register wie z.B. H tut es auch, denn 0-255 Jahre reichen völlig. Das hängt damit zusammen, dass der PM eine 8 Bit CPU besitzt. Das heißt, der Datenbus ist 8 Bit breit. Somit können vom Processor nur 8 Bit gleichzeitig verarbeitet werden. Bei 24 Bit bräuchte er das dreifache an Rechenzeit und Rechenzeit ist kostbar.
Besonderheiten
Die Register X1, X2 und HL sind bekanntermaßen 24 Bit Register. Es ist
nicht möglich die 24 Bit mit einem Befehl zu schreiben bzw. auszulesen. Möchte
man z. B. in X1 die 24 Bit Adresse 0x123456 abspeichern, muss man 2 MOV Befehle
einsetzen:
movx x1, 0x12 mov x1, 0x3456
Das gilt auch für X2 und HL. MOVX steuert dabei die oberen 8 Bit an, und MOV die unteren 16 Bit. Auch andere Befehle die als Präfix ein X besitzen, steuern die oberen 8 Bit dieser Register an.
Grundlagen
Zu aller erst müssen wir den Befehl MOV kennen. MOV steht für das englische Move – Bewegen. In unserem Fall kopieren wir den Wert der Quelle ins Ziel hinein. Es gibt beim PM 26 verschiedene MOV-Befehle, diese alle zu erwähnen wäre hier sinnlos, man kann sie in der mindx.txt nachlesen. Wichtig ist für uns, dass MOV 2 Parameter besitzt, das erste ist das Ziel, und das Zweite ist die Quelle.
mov a, 10
Hier wird die 10 - unsere Quelle in das Ziel - Register A kopiert. Ist dieser Befehl abgearbeitet, steht in Register A die Dezimalzahl 10. Weiter brauchen wir ein sogenanntes Framework für unsere Programme. Ein Framework ist so zu verstehen, das es immer in unser Programm eingebunden werden muss, und es nicht verändert wird(gut bis auf Titel und Code)). Es sieht folgendermaßen aus:
.orgfill 0x0009A jmp main .orgfill 0x02100 .db "MN" .orgfill 0x021A4 .db "NINTENDO" ; Groß- und Kleinschreibung beachten! .db "Code" ; Programmcode .db "Titel" ; Titel darf maxmimal 12 Zeichen groß sein .orgfill 0x021BC .db "2P" .orgfill 0x021D0 main: ; Hier kommt der eigentliche Code hinein end: jmp end
Ohne dieses Framework würde der PM das Programm nicht anerkennen. Für uns ist erst einmal nur wichtig, was zwischen main: und end: steht. Den Programmcode und Titel kann man jedoch nach belieben verändern.
Kommentare
In einem Assemblercode der sich über 10.000 Zeilen erstreckt, sollte man Kommentare im Code benutzen, der den jeweiligen Part beschreibt. Sie werden mit einem einfachen Semikolon eingeleitet. Alles was hinter diesem Semikolon steht, wird beim Übersetzen von Assembler- in Maschinencode vernachlässigt, wird also auch nicht in den Maschinencode mit eingebunden.
Zahlensysteme
Irgendwie will man seine neugewonnenen Kenntnisse in Sachen Zahlensysteme auch anwenden können, deswegen bietet pmas Assembler folgende Präfixe:
0x und $ für Hexadezimalzahlen. | Beispiel: 0x2081 0b für Binärzahlen. | Beispiel: 0b00010111 Ohne Suffix sind normale Dezimalzahlen. | Beispiel: 123
Man kann die Zahlensysteme auch vereinen, z.B. ergibt 0x20 + 0b1111 = 30h
Im Debugger werden alle Werte nur im Hexadezimalsystem angezeigt.
Grundrechenarten
Nicht um sonst heißt der Computer, Computer. Compute steht für Rechnen, und das kann ein Computer nun mal. Nicht nur der PC im Büro sondern auch unser kleiner PM. Er unterstützt die 4 Grundrechenarten Addition, Multiplikation, Division und Subtraktion. Der PM ist CMOS basierend. CMOS steht für Complementary Metal-Oxide Semiconductor(komplementärer Metalloxid - Halbleiter). Diese Technologie kann nur mit 2 Zuständen arbeiten. Highpegel und Lowpegel. Also arbeitet er auf binärer Ebene. Aber wie werden 2 Zahlen eigentlich addiert?
Beispiel: A = 10d = 1010b; B = 2d = 0010b
1010 | 0 + 0 = 0 + 0010 | 1 + 1 = 0 | Merke 1 ------ | 0 + 0 = 0 + Merke 1 = 1 1100 | 1 + 0 = 1
1100b = 12d. Für die Addition zweier Zahlen steht uns der Befehl ADD – Addition zur Verfügung.
Programmtechnisch siehe das Beispiel folgendermaßen aus:
main: mov a, 10 mov b, 2 add a, b ; a = a + b .end
Subtraktion
Bei der Subtraktion sieht es da schon etwas komplizierter aus, denn intern rechnet er nicht schriftlich sondern bildet erst das Komplement des Subtrahenden und addiert dieses zum Minuend hinzu. Der Übertrag an höchster Stelle wird weggestrichen. Existiert kein Übertrag, wird vom Ergebnis der Addition das Komplement gebildet und mit einem negativen Vorzeichen versehen.
Beispiel: A= 10d = 1010b; B = 4d = 0100b
Komplement von 0100b ist 0100b 1010 + 0100 ------ 01110
Die linken 2 Bits werden gestrichen: 00110b = 6d. In Assembler gibt es dazu den Befehl SUB, abgeleitet von Subtraction also Subtraktion.
main: mov a, 10 mov b, 4 sub a, b ; a = a - b .end
Multiplikation
Die Multiplikation wird intern wieder schriftlich gerechnet.
Beispiel: A = 12d = 1100b; B = 6d = 0110b
1100 * 01100 ------------ 0000 + 1100 + 1100 + 0000 + 0000 ------------ 01001000
1001000b = 72d. Der Befehl MUL – abgeleitet von Multiplication also Multiplikation kann 2 Zahlen miteinander multiplizieren. Zu beachten ist, das er nur die Register A und L miteinander multiplizieren kann, andere Register sind nicht zulässig. Das Ergebnis wird dann in Register HL gespeichert.
main: mov l, 12 mov a, 6 mul l, a ; hl = l * a .end
Division
Auch hier darf man nur mit 2 vorgewiesenen Registern arbeiten. HL und A. Der benötigte Befehl heißt DIV – Division. Wollen wir unsere 72 wieder durch 6 teilen nehmen wir folgendes Programm:
main: mov hl, 72 mov a, 6 div hl, a ; hl = hl / a .end
In Register HL sollte nun 0x0C also 12d stehen.
Shiften
Shiften steht für verschieben. Man kann also Bits nach links oder rechts verschieben. Was hat das aber für ein Sinn? Nun, nehmen wir doch mal die binäre Zahl 1000b = 8d und verschieben die Bits um eine Stelle nach links(rechts wird dann mit Nullen aufgefüllt) also 10000b = 16b. Wir sehen, die Acht verdoppelt sich. Verschieben wir die Bits von 1000b um eine Stelle nach rechts(links wird wieder mit Nullen aufgefüllt, rechts werden die Bits gestrichen) = 0100b ergibt dies 4d. Es wird also eine Division durch 2 durchgeführt. Aufgrund der Architektur der CPU sind Shifts schneller als das Verwenden der Befehle MUL und DIV. Shiften kann man beliebig oft.:
01110000 >> 1 = 00111000 >> 1 = 00011100 >> 1 = 00001110 >> 1 = 00000111 >> 1 = 00000011 >> 1 = 00000001 >> 1 = 00000000 >> 1 00011100 << 1 = 00111000 << 1 = 01110000 << 1 = 11100000 << 1 = 11000000 << 1 = 10000000 << 1 = 00000000 << 1
Eine Multiplikation von 6 * 7 kann man so lösen, dass man 6 * 8 rechnet, also 6 dreimal nach links shiftet und dann 6 vom Ergebnis abzieht. Der Befehl zum links Shiften heißt SHL – Shift Left – verschiebe nach links und zum rechts Shiften SHR – Shift Right – verschiebe nach rechts.
main: mov a, 6 mov b, a ; kopiere a in b shl a ; a = a*2 shl a ; a = a*2 shl a ; a = a*2 sub a, b ; a = a-b end: jmp end
Am Ende wird 48 – 6 = 42 gerechnet. 6 * 7 = 42.
Jetzt wissen wir ja, dass bei den Registern das höchste Bit als Vorzeichenbit intern genommen wird. Durch Shifts wird jedoch auch dieses mit verschoben. Die Folge ist, das unterschiedliche Vorzeichen auftreten. z. B. bei 10001011b = -11d. Schiebt man diese Bitreihenfolge nach links entsteht die Zahl 00010110b = +11d oder auch beim Rechtsschieben entsteht 010001011b = +139d. Deswegen besitzt der PM 2 Befehle die das Vorzeichenbit garnicht beachten und somit bei einem 8 Bit Wert nur 7 schieben. Diese heißen SAL für das Linkschieben und SAR für das Rechtschieben.
main: mov a, -8 ; A = 0xF8 = 0b11111000 = -8 sar a ; A = 0xFC = 0b11111100 = -4 mov a, -8 ; A = 0xF8 = 0b11111000 = -8 shr a ; A = 0x78 = 0b01111100 = +120 Vorzeichenfehler ! end: jmp end
Rotieren
Eine weitere Eigenart des Schiebens ist das Rotieren. In fast keiner Hochsprache gibt es einen Operator für diese Technik, sie ist auch in vielen Fällen nicht notwendig. Aber man sollte wissen wie es funktioniert. Es gibt beim Rotieren wieder zwei Richtungen(links, rechts), jedoch wird beim Schieben nicht ein Bit "weggeworfen" und eine Null nachgeschoben. Sondern das "weggeworfene" Bit wird auf der anderen Seite nachgeschoben. Man kann sich das am einfachten als Ring vorstellen.
Beispiel 11010110b nach links rollen
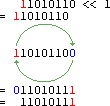
Das geht natürlich auch mit dem Rechtsrollen. Das rechte Bit wird aufgehoben und links wieder angehangen. Die beiden Befehle dazu heißen ROL - Rotate Left und ROR - Rotate Right.
main: mov a, 0b11010110 ; Register A den Wert 0b11010110 zuweisen rol a ; A = 0b11010111 = (0b11010110 SHL 1) OR (0b11010110 SHR 7) end: jmp end
Auch ein Rotieren über das Carryflag ist möglich. Dabei wird beim Rotieren auf der anderen Seite das Carryflag angehangen und danach das herausfallende Bit im Carryflag gespeichert. Dafür gibt es die beiden Befehle ROLC - Rotate Left with Carry und RORC - Rotate Right with Carry.
Inkrementieren / Dekrementieren
Klingt schlimmer als es ist. Inkrementieren und Dekrementieren kommen aus dem Lateinischen und stehen für incrementare – der Zuwachs und crementare – der Verfall / die Verminderung. Für diese beiden Aufgaben gibt es die Befehl INC und DEC. INC erhöht also einen Wert um 1, und DEC vermindert ihn um 1. Diese beiden sind z. B. nützlich, wenn man mehrere Bytes von einer Adresse in die andere kopieren möchte. Aufgrund der CPU Architektur ist INC schneller als ADD und DEC schneller als SUB.
main: mov a, 4 dec a ; a = a-1 dec a ; a = a-1 dec a ; a = a-1 dec a ; a = a-1 inc a ; a = a+1 inc a ; a = a+1 end: jmp end
Logische Bitverknüpfungen
In unserem Leben tauchen eine Vielzahl von logischen Verknüpfungen auf. Die mathematische Logik basiert nur auf 2 Wahrheitswerten – Wahr oder Falsch – 1 oder 0. Nehmen wir z. B. ein alltägliches Beispiel: Sie wollen ins Bett gehen, wollen vorher jedoch Zähne geputzt und Wecker gestellt haben. Die logische Verknüpfung zwischen Zähne geputzt und Wecker gestellt wäre in dem Fall UND. Nur dann wenn Sie Zähne geputzt haben UND den Wecker gestellt haben, gehen Sie ins Bett. Aufgrund dessen das sich die Logik mit nur 2 Wahrheitswerten beschäftigt, kann man sie auch in der Programmierwelt ansiedeln. Besonderen Einsatz findet die Logik z. B. in der SPS Programmierung. Man hat 2 Schalter und eine Glühlampe. Wenn min. einer der beiden Schalter gedrückt wird, leuchtet die Lampe auf. Diese Verknüpfung wäre ein logisches ODER, genauer ein inklusives ODER.
Zur Auswahl stehen die logischen Bitoperationen UND, inklusiv ODER, exklusiv ODER und NICHT. Operanden mit 2 Parametern heißen binäre- und mit einem Parameter heißen unäre Operanden. Auch hier verwendet man wieder englische Begriffe. UND wird zu AND, inklusiv ODER wird zu OR, exklusiv ODER wird zu XOR und NICHT zu NOT.
w(p) | w(q) | w(q AND p) | w(q OR p) | w(p XOR p) | w(NOT p) ------+------+------------+-----------+------------+--------- W | W | W | W | F | F W | F | F | W | W | F F | W | F | W | W | W F | F | F | F | F | W
Bei exklusiv ODER ist das Ergebnis nur wahr, wenn beide Parameter verschieden sind. NOT ist ein unärer Operand und invertiert - kehrt den Wahrheitswert um.
Das Flagregister
Wie schon gesagt, wird das Flagsregister auch als Statusregister bezeichnet. In ihm wird also der Status der CPU abgespeichert. Er ist 8 Bit groß und hat folgenden Aufbau:
+--------------------------------------+ |IE | ?? | LM | BM | SF | OF | CF | ZF | +--------------------------------------+
IE: Interrupt Enable - hier wird festgelegt, ob Interrupts ausgeführt werden dürfen
??: Unbekannt - hat wahrscheinlich keinen Nutzen
LM: Low Mask - wenn ein zu vergleichender Wert kleiner war
BM: Binary Codet Digit Mode - In diesem Modus wird für eine Ziffer des Dezimalsystems 1 Byte
benutzt – findet kaum Anwendung.
SF: Signed Flag - wenn das Ergebnis einer Rechenoperation negativ war
OF: Overflow Flag - wenn es bei einer Rechenoperation zu einem Überflauf gekommen ist
CF: Carry Flag - wird z. B. beim Übertrag einer Addition benutzt
ZF: Zero Flag - wenn das Ergebnis einer Rechenoperation 0 ist
Welches Flag genau von welchem Befehl beeinflusst wird, steht in der mindx.txt.
Der Stack
Den Stack darf man sich wie ein Stapel voller Bücher vorstellen. Man kann ein Buch auf ihn ablegen, und nur das oberste wieder herunternehmen. Dies wird in der Fachsprache als LIFO – Last In First Out Prinzip bezeichnet. Pushen bedeutet bei uns das Ablegen, und Popen das wieder Herunternehmen eines Wertes. Wo liegt der Nutzen im Stack? Wenn wir dann zu den Prozeduren kommen, benötigen wir auch Übergabeparameter. Für die ganzen Parameter Register zu belegen, würde die Sauberkeit des Quellcodes enorm beeinträchtigen, zudem auch für eine große Anzahl an Parametern nicht genügend Register zur Verfügung stehen. Deswegen legt man alle Parameter auf den Stack ruft die Prozedur auf, und die Prozedur kann diese Parameter wieder herunternehmen.
2 Parameter Hinauflegen:
+------------------+ +------------------+ +------------------+ | leer | | leer | | leer | +------------------+ +------------------+ +------------------+ | leer | | leer | | leer | +------------------+ +------------------+ +------------------+ | leer | | leer | | leer | +------------------+ +------------------+ +------------------+ | leer | | leer | | Parameter 2 | <- SP +------------------+ +------------------+ +------------------+ | leer | | Parameter 1 | <- SP | Parameter 1 | +------------------+ +------------------+ +------------------+ | Null-Element | <- SP | Null-Element | | Null-Element | +------------------+ +------------------+ +------------------+
und wieder Herunternehmen:
+------------------+ +------------------+ +------------------+ | leer | | leer | | leer | +------------------+ +------------------+ +------------------+ | leer | | leer | | leer | +------------------+ +------------------+ +------------------+ | leer | | leer | | leer | +------------------+ +------------------+ +------------------+ | Parameter 2 | <- SP | Parameter 2 | | Parameter 2 | +------------------+ +------------------+ +------------------+ | Parameter 1 | | Parameter 1 | <- SP | Parameter 1 | +------------------+ +------------------+ +------------------+ | Null-Element | | Null-Element | | Null-Element | <- SP +------------------+ +------------------+ +------------------+
Wie in der 2. Abbildung zu sehen sein sollte, werden die Einträge keineswegs beim Herunternehmen gelöscht. Das hat den Grund, dass das Löschen zusätzliche Rechenleistung kostet. Stattessen werden die Werte einfach beim nächsten Hinauflegen durch die neuen Werte überschrieben, was auch bei einem leeren Element geschieht.
Bei jedem Hinauflegen wird der Stackpointer um eins dekrementiert, und bei jedem herunternehmen um eins inkrementiert. Wenn er auf das Null-Element zeigt, hat er den Wert 0x002000, beim Parameter 1 den Wert 0x001FFF und beim Parameter 2 den Wert 0x001FFE. Das De- bzw. Inkrementieren um 1 geschieht jedoch nur bei Bytewerten. Wird z. B. das 16 Bit Register BA auf in geladen, werden ja 2 Byte benötigt, somit der Stackpointer auch um 2 vermindert.
main: mov a, 0x10 ; Register A = 0x10 mov b, 0x20 ; Register B = 0x20 ; Register A und B auf den Stack legen push a push b ; Nun können die Register beliebig beschrieben werden. mov a, 0x12 mov b, 0x34 ; Werte wieder zurück in die Register schreiben pop b pop a end: jmp end
Wie man erkennen kann, muss nach dem Ablegen von A und B zuerst B wieder herunter genommen werden und erst dann A.
Das Ablegen der 24 Bit Register X1, X2 und HL erfolgt gesondert. Wie wir bereits wissen, kann man diese Register nicht mit einem Befehl komplett ansteuern. Man muss die oberen 8 Bit und die unteren 16 Bit gesondert sehen. Für den Register HL gibt es die beiden Befehle PUSHX und POPX um die oberen 8 Bit des Register anzusprechen, bei X1 und X2 muss man vorher die oberen 8 Bit in ein 8 Bit Register(z. B. Register A) auslagern.
main: ; Das ganze funktioniert auch mit X2! ; X1 einen 24 Bit Wert zuweisen movx x1, 0x12 ; X1 = 0x120000 mov x1, 0x3456 ; X1 = 0x123456 ; X1 auf den Stack legen movx a, x1 ; A = 0x12; popx x1 geht nicht! push a ; 0x12 auf den Stack legen push x1 ; 0x3456 auf den Stack legen ; X1 den 24 Bit Wert 0 zuweisen movx x1, 0 ; HL = 0x003456 mov x1, 0 ; HL = 0x000000 ; X1 vom Stack herunternehmen pop x1 ; X1 = 0x003456 pop a ; A = 0x12 movx x1, a ; X1 = 0x123456 end: jmp end
main: ; HL einen 24 Bit Wert zuweisen movx hl, 0x12 ; HL = 0x120000 mov hl, 0x3456 ; HL = 0x123456 ; HL auf den Stack legen pushx hl ; 0x12 auf den Stack legen push hl ; 0x3456 auf den Stack legen ; HL den 24 Bit Wert 0 zuweisen movx hl, 0 ; HL = 0x003456 mov hl, 0 ; HL = 0x000000 ; HL vom Stack herunternehmen pop hl ; HL = 0x003456 popx hl ; HL = 0x123456 end: jmp end
Anzumerken gilt, das man auch oft nur mit den unteren 16 Bit auskommt, wenn das Programm nicht die 64 KByte Marke überschreitet.
Adressen
Im PM wird alles über den RAM - Random Access Memory organisiert. Unser Programm liegt in ihm, man kann über bestimmte Adressen Hardwarefunktionen wie z. B. die Ausgabe am Display steuern, Variablen in ihm ablegen und unser Stack wird auch in ihm gespeichert. Um einzelne Adressen anzusteuern bietet der PM eine menge Möglichkeiten. Zu beachten ist, dass man nie einen Wert direkt in eine Speicherzelle kopieren kann, sondern man immer zuerst den Wert oder die Adresse in ein Register ablegen muss. Adressen werden im pmas durch zwei eckige Klammern gekennzeichnet []. Möchte man z. B. den Wert 0x10 in die Speicherzelle an Adresse 0x001234 kopieren, kopiert man den Wert 0x10 in das Register A, und dann sagt dann MOV [0x001234], A.
Der PM kennt noch andere Adressierungsarten mit Register:
[X1+ofs8] [X1+L] [X2+ofs8] [X2+L] [NN+ofs8] [HL] [X1] [X2]
ofs8 steht für Offset8, also ein Versatz mit 8 Bit. [X1+0x24] - Nehmen wir an, dass in X1 der Wert 0x001210 steht. Die resultierende Adresse aus 0x001210 + 0x24 wäre hier 0x001234. Wir würden also 0x001234 ansteuern. NN ist ein Sonderfall da N eigentlich ein 8 Bit Register ist. Steht in N 0x12 und im Offset 0x34 ergibt sich daraus die Adresse 0x001234 es wird also intern nicht addiert sondern N um 8 Bit nach links verschoben.
Nun gut, machen wir gleich etwas Praktisches und steuern den LCD Kontrast an. Er geht von 0x00(weiß auf weiß) bis 0x3F(schwarz auf schwarz) und hat somit eine Auflösung von 64 Werten. 0x1F ist der normale Kontrast. Laut mindx.txt muss in die Adresse 0x0020FE der Wert 0x81 und in Adresse 0x0020FF der Kontrastwert.
main: mov a, 0x81 ; LCD Hardwareregister mov b, 0x2F ; gräulicher Kontrast mov [0x0020FE], a ; [0x0020FE] = A mov [0x0020FF], b ; [0x0020FF] = B end: jmp end
Später kann man mit Hilfe des Kontrastes Blendeffekte im seinem Programm realisieren und sogar kleine Slideshows programmieren.
Labels
Wer in BASIC programmiert, der wird sicherlich Labels schon kennen. Oft verhasst wegen unsauberer Codeverunstaltung durch Goto, in Assembler jedoch unabdingbar. Labels sind Sprungadressen innerhalb des Codes. Sie nehmen kein Extraspeicher und werden durch einen Doppelpunkt gekennzeichnet. main: z. B. ist ein Label. Im Gegensatz zu modernen BASIC Sprachen sorgen Labels hier für Sauberkeit im Code. Wenn wir uns mal irgendeine *.min Datei von unseren letzten Projekten im Hexeditor anschauen, werden wir feststellen, das an Adresse 0x0021BC der String "2P" steht, danach 18 Byte mit dem Wert 0x00 gefüllt sind und dann unser assembelierter Machinencode in Adresse 0x0021D0 steht. 0x0021D0 ist somit die Adresse für das main: Label.
Variablen
Bisher hatten wir nur mit Register gearbeitet. Register sind zwar schnell anzusteuern, jedoch begrenzt. Deswegen benutzt man Variablen. Man kann Variablen nur in den WorkRAM speichern. Der WorkRAM ist 2976 Byte groß das sind ca. 2,9 KBytes. Das ist ausreichend, denn das Programm wird nicht wie beim PC auch in den WorkRAM geladen, sondern bleibt auf dem Siielmodul also dem ROM - Read Only Memory der nur gelesen werden kann. Der Nachteil, Variablen können nicht vorher initalisiert werden, sie bekommen somit am Anfang irgendein beliebigen Wert zugewiesen, der gerade an dieser Speicherstelle aktuell ist. In pmas gibt es folgende Datentypen:
.db Byte = 8 Bit groß .dw Word = 16 Bit oder 2 Byte groß .dd Double = 32 Bit oder 4 Byte oder 2 Word groß
Eine Variable hat folgende 4 Eigenschaften:
- Deklarieren: Dem Assembler klar machen das eine Variable benötigt wird. - Datentyp: Wieviel Speicher verlangt die Variable? - Name: Der Name der Variable, festgelegt durch den Labelnamen.- Speicheradresse: Adresse im Speicher, indirekt festgelegt durch den Assembler.
Wollen wir z. B. die X- und Y-Position des Spielheldens als 2 Word Variablen festlegen, sagen wir folgendes:
.orgfill 0x0009A jmp main ; VideoRAM von 0x001000 - 0x00145F .orgfill 0x1460 ; hier beginnt der WorkRAM für alle Variablen held_x: .dw held_y: .dw .orgfill 0x02100 .db "MN" .orgfill 0x021A4 .db "NINTENDO" .db "1234" .db "Spritetest" .orgfill 0x021BC .db "2P" .orgfill 0x021D0 ...
Der Zugriff erfolgt so:
main: ; Werte zuwesein mov ba, 20 mov [held_x], ba ; Variable Held_X den Wert 20 zuweisen mov ba, 30 mov [held_y], ba ; Variable Held_Y den Wert 30 zuweisen ; Werte auslesen mov ba, [held_x] ; in BA steht jetzt der Wert von Held_X mov ba, [held_y] ; in BA steht jetzt der Wert von Held_Y end: jmp end
Der folgende Abschnitt ist inhaltlisch falsch, muss ich nochmal überarbeiten....
Auch mehrere Werte wie z.B. das Übergeben eines Strings erkennt der Assembler:
nachricht: .db "Hallo Welt!", 0
Die 0 bedeutet hier, das der String mit einem 0 abgeschlossen wird. Es gibt viele Stringarten, und diese Art heißt 0-Terminated String wie vieleicht den ein oder anderen das ganze aus C/C++ bekannt ist. pmas ersetzt jedes Zeichen, auch das Leerzeichen durch den jeweiligen ASCII Code. Der ASCII Code soll jetzt hier nicht näher erleutert werden, nur soviel, jedes Zeichen hat in dem Code sein eigenen Wert.
Unbedingte Sprünge
Bei Sprüngen wird von einem Code zum anderen Gesprungen. Dabei gibt man als Zieladresse Sprungmarken also Labels an. Einen ersten Sprung machen wir schon in unserem Framework durch JMP main. Der PM prüft erst ob die ganzen Sachen wie "MN", "NINTENDO", "2P" etc. in dem ROM vorhanden sind, springt zu Adresse 0x00009A und führt den Code ab dieser Stelle aus. In dieser Adresse steht jmp main, dies verhindert, das er z. B. dann den String "MN" als Befehl auswertet. JMP steht für Jump also Sprung, mit diesem Befehl ist es möglich an jede Stelle des Programms zu Springen.
main: mov a, 0x00 ; Register A = 0x00 jmp label ; Sprung zur Sprungmarke Label mov a, 0x10 ; wird nicht ausgeführt label: mov a, 0x20 ; Register A = 0x20 end: jmp end
Hier wird zuerst den Register A der Wert 0x00 zugewiesen, dann zum Label gesprungen. Im Label wird Register A der Wert 0x20 zugewiesen und das Programm sofort beendet. MOV A, 0x10 wird somit einfach übersprungen.
Bedingte Sprünge
Bisher wurden unsere Sprünge immer ausgeführt. Jedoch kann man auch Sprünge in Abhängigkeit ausführen lassen. Diese Abhängigkeit wird dabei auf den Statusregister zurückgeführt. Es gibt Befehle die nur einen Sprung ausführen wenn bestimmte Flags im Statusregister gesetzt sind, und welche nur dann einen Sprung ausführen, wenn bestimmte Flags nicht gesetzt ist.
In engen Zusammenhang mit den bedingten Sprüngen steht der CMP - Compare - Vergleiche Befehl. Er subtrahiert den zweiten Wert vom ersten und setzt bzw. löscht die entsprechenden Flags im Statusregister. Sagen wir das Register A hat den Wert 10 und das Register B ebenfalls 10, dann würde CMP A, B das Zeroflag setzen, da 10-10 = 0 ist.
Folgende Sprungbefehle stehen dem Programmierer zur Verfügung:
Befehl | Bedeutung | Bedingung --------+-------------------------------------------------------------+--------------------- jl | Jump if lower - Springe wenn kleiner | SF <> OF jle | Jump if lower or equel - Springe wenn kleiner oder gleich | ZF = 1 oder SF <> OF jg | Jump if greater - Springe wenn größer | ZF = 0 und SF = 0 jge | Jump if greater or equel - Springe wenn kleiner oder gleich | SF = OF jo | Jump if overflow - Springe wenn Überlauf | OF = 1 jno | Jump if not overflow - Springe wenn kein Überlauf | OF = 0 js | Jump if signed - Springe wenn Vorzeichen | SF = 1 jns | Jump if not signed - Springe wenn kein Vorzeichen | SF = 0 jc | Jump if carry - Springe wenn Carry | CF = 1 jnc | Jump if not carry - Springe wenn nicht Carry | CF = 0 jz | Jump if zero - Springe wenn 0 | ZF = 1 jnz | Jump if not zero - Springe wenn ungleich 0 | ZF = 0
Wenn ein Sprung ausgeführt wird, wird zugleich auch das Register U in das Register V kopiert. Der Sinn dabei wurde noch nicht herausgefunden.
Jetzt können wir uns Vergleichstrukturen Programmieren. Einfach zu realisieren wäre z. B. zu Prüfen, ob Register A = Register B ist.
main: mov a, 10 ; Register A = 10 mov b, 10 ; Register B = 10 ; Vergleiche A mit B cmp a, b jz wenn_gleich ; bei A = B jnz wenn_ungleich ; bei A <> B wenn_gleich: mov h, 0x12 ; Register H = 0x12 jmp ende ; zum Ende springen wenn_ungleich: mov h, 0x34 ; Register H = 0x34 jmp ende ; zum Ende springen ende: .end
Register A und B sind gleich, deswegen steht am Ende in Register H der Wert 0x12, ändert man jetzt B auf 11 ab, so ist A und B ungleich und in Register H steht dann der Wert 0x34.
Schleifen
Schleifen treten dann auf, wenn eine bestimmte Anweisung wiederholt werden soll. Spätestens dann in der Spieleschleife wo ständig die Eingabe des Benutzers geprüft und ausgewertet werden soll, wird man Kontakt mit einer Schleife haben. Es gibt verschiedene Schleifentypen die jedoch alle den gemeinsamen Nenner Label und Sprung haben. Unser Label wird als Schleifenkopf, unsere Sprunganweisung Schleifenfuß und alles was sich zwischen Kopf und Fuß befindet Schleifenkörper genannt.
Repeat - Forever - Schleife
Sie ist die einfachste von allen Schleifen. Weil sie unendlich lang ausgeführt wird, benötigt keinen bedingten Sprung. Somit kann hier die Sprunganweisung JMP genommen werden.
main: mov a, 1 ; Startwert 1 festelegen. schleifenkopf: ; Schleifenkopf als Label. inc a ; Schleifenkörper als simple Anweisung. ; Hier könnten jetzt mehr Anweisungen stehen. jmp schleifenkopf ; Schleifenfuß als unbedingt Sprunganweisung. end: jmp end ; wird erst garnicht ausgeführt
Übrigens, inc a wird irgendwann zu einem Überlauf führen, dann wird einfach wieder bei 0 beginnend an weiter gezählt.
For - Next - Schleife
Diese Schleife kommt immer dann zum Einsatz, wenn die Anzahl an Durchläufen bekannt ist. Als Zählvariable kann man entweder eine definierte Variable im RAM, oder ein Register benutzen. Diese wird vom Startwert bis zum Endwert hochgezählt. Sie hat somit die Bedingung Zählvariable < Endwert. Sie wird häufig eingesetzt, wenn Speicher von einem Ort zum anderen kopiert werden soll.
main: mov a, 1 ; Startwert mov b, 100 ; Register B = 100 schleifenkopf: ; Schleifenkopf dec b ; Schleifenkörper inc a ; Register A um 1 erhöhen cmp a, 10 ; Register A mit dem Endwert 10 vergleichen. jl schleifenkopf ; Wenn Register A kleiner als 10, dann weiter machen. end: jmp end
Diese Schleife wird 10 mal wiederholt. Manchmal ist es auch nötig von z. B. 10 auf 1 herunter zu Zählen, dann darf man halt nicht INC sondern DEC und JG statts JL benutzen.
While - Wend - Schleife
Die While - Wend - Schleife ist eine anfangsbedingte Schleife. D. h. sie wird solange ausgeführt, solange die Bedingung im Schleifenkopf nichtmehr erfüllt wird. Stimmt die Bedingung schon vor Ablauf der Schleife nicht, wird sie somit auch erst garnicht ausgeführt.
main: mov a, 1 ; Register A = 1 schleifenkopf: ; Schleifenkopf cmp a, 10 ; Schleifenbedingung: Register A ungleich 10 jz schleifenfuss ; Ist Bedingung nicht erfüllt, dann springe zu Schleifenfuss. inc a ; Schleifenkörper jmp schleifenkopf ; Schleifenkörper schleifenfuss: ; Schleifenfuss end: jmp end
Setzen wir statts 1 mal 10 ein, so werden wir sehen, dass die Schleife erst garnicht ausgeführt wird.
Repeat - Until - Schleife
Diese Schleife verhällt sich änlich der While - Wend - Schleife, jedoch wird sie mindestens einmal durchgelaufen. Das liegt daran, das die Bedingung am Ende des Schleifenkörpers steht.
main: mov a, 1 ; Register A = 1 schleifenkopf: ; Schleifenkopf inc a ; Schleifenkörper cmp a, 10 ; Schleifenbedingung: Register A ungleich 10 jnz schleifenkopf ; Wenn Bedingung erfüllt, dann springe zu Schleifenkopf. end: jmp end
Prozeduren
Prozeduren sind vom Programmierer definierte Funktionen die häufig benutzt werden. Dabei arbeitet man mit Übergabewerten auch als Attribute oder Parameter bezeichnet. Oft kommt es z. B. vor das man Werte von einer Adresse zur anderen kopieren muss. Hierfür schreibt man sich eine Funktion der man die Parameter Quelladresse, Zieladresse und Länge in Byte übergibt. Diese Übergabeparameter kann man jetzt am einfachsten in Register schreiben, da Register überall im Quellcode Gültigkeit haben, oder man lädt die Parameter auf den Stack was jedoch viel Logik mit sich zieht.
Prozeduren werden durch Call - Anweisungen aufgerufen. Calls funktionieren wie Sprunganweisungen jedoch sichern sie auf den Stack vorher die Rücksprungadresse. Mittels RET - Return kann dann an der Stelle nach dem Aufruf im Hauptprogramm fort gefahren werden. Wer mit BASIC schon gearbeitet hat, der darf sich Call Anweisungen als Gosub- und RET Anweisungen als Return Befehl vorstellen. Call lässt sich von Aufruf ableiten, man ruft also eine Prozedur auf. Dabei gibt es auch wieder unbedingte und bedingte Aufrufe. Sie sind identisch mit den Sprungbefehlen. Das einfache CALL ersetzt den Sprungbefehl JMP, CALLNZ ersetzt den Sprungbefehl JNZ, CALLC ersetzt JC usw.
main: mov a, 0x10 ; a = 0x10 call prozedur1 ; a = 0x20 call prozedur2 ; a = 0x30 call prozedur3 ; a = 0x40 mov a, 0x50 ; a = 0x50 jmp end ; Springe zum Ende prozedur1: mov a, 0x20 ret ; mache im Hauptprogramm weiter prozedur2: mov a, 0x30 ret ; mache im Hauptprogramm weiter prozedur3: mov a, 0x40 ret ; mache im Hauptprogramm weiter end: jmp end
Wenn man sich jetzt den Stackpointer vor und nach einem Aufruf einer Prozedur ansieht, kann man erkennen, das irgendwas auf ihn abgelegt wird. Das ist wie gesagt die Rücksprungadresse. CALL kann somit durch PUSH und JMP ersetzt werden. RET durch POP und JMP.
Parameterübergabe per Stack
Dieser Abschnitt erfordert etwas mehr Logik. Wir wissen ja, das der Stack ein Stapelspeicher ist. Auf ihn werden Werte abgelegt und wieder herunter genommen. Es ist üblich vor Aufruf einer Prozedur die entsprechenden Übergabeparameter auf den Stack abzulegen. Das Problem ist, wenn wir eine Call Anweisung aufrufen, dann auf den Stack die Rücksprungadresse gelegt wird.
+------------------+ | leer | +------------------+ | Rücksprungadr. | <- SP +------------------+ | Parameter 1 | +------------------+ | Parameter 2 | +------------------+ | Parameter 3 | +------------------+ | Null-Element | +------------------+
Würden wir jetzt versuchen, auf Parameter 1 in unserer Prozedur zu zugreifen, müssten wir zwangsweise auch die Rücksprungadresse vom Stack herunternehmen und der Programm Counter wird dann am Arsch der Welt plaziert werden. Man könnte jetzt natürlich den SP auf Parameter 1 zeigen lassen, jetzt hätten wir jedoch das Problem, wenn wir in der Prozedur entweder lokale Variablen ablegen, oder andere Prozeduren ansteuern möchten, die Rücksprungadresse überschrieben werden könnte. Wir müssen uns somit ein anderes Managment ausdenken was sehr kompliziert ist. Unser Ziel muss sein, das die Parameter an oberster Stelle stehen. Das kann man realisieren, in dem man den SP vor Aufruf einer Prozedur manipuliert.
sub sp, 3 ; Platz für Rücksprungadresse machen mov ba, 0x1234 ; Parameter 1 festlegen push ba ; Parameter 1 auf den Stack legen mov ba, 0x4321 ; Parameter 2 festlegen push ba ; Parameter 2 auf den Stack legen mov ba, 0x5678 ; Parameter 3 festlegen push ba ; Parameter 3 auf den Stack legen add sp, 9 ; SP vor den 3 Parametern plazieren für Rücksprungadresse call prozedur ; Prozedur aufrufen
add sp, 9 kommt daher zu Stande, da wir hier 3 16 Bit Werte = 6 Byte auf den Stack ablegen, und 3 Byte nocheinmal die Rücksprungadresse erfordert. Also 3*2+3 = 9 Byte insgesamt.
Was geschieht hier?
+------------------+ | leer | +------------------+ | leer | +------------------+ | leer | +------------------+ | leer | +------------------+ | leer | +------------------+ | Null-Element | <- SP +------------------+
sub sp, 3 :
+------------------+ | leer | +------------------+ | leer | +------------------+ | leer | +------------------+ | leer | +------------------+ | leer | <- SP +------------------+ | Null-Element | +------------------+
push ba :
+------------------+ | leer | +------------------+ | leer | +------------------+ | leer | +------------------+ | 0x1234 | <- SP +------------------+ | leer | +------------------+ | Null-Element | +------------------+
push ba :
+------------------+ | leer | +------------------+ | leer | +------------------+ | 0x4321 | <- SP +------------------+ | 0x1234 | +------------------+ | leer | +------------------+ | Null-Element | +------------------+
push ba :
+------------------+ | leer | +------------------+ | 0x5678 | <- SP +------------------+ | 0x4321 | +------------------+ | 0x1234 | +------------------+ | leer | +------------------+ | Null-Element | +------------------+
add sp, 9 :
+------------------+ | leer | +------------------+ | 0x5678 | +------------------+ | 0x4321 | +------------------+ | 0x1234 | +------------------+ | leer | +------------------+ | Null-Element | <- SP +------------------+
call prozedur:
+------------------+ | leer | +------------------+ | 0x5678 | +------------------+ | 0x4321 | +------------------+ | 0x1234 | +------------------+ | Rücksprungadr. | <- SP +------------------+ | Null-Element | +------------------+
Jetzt sind die Parameter wie gewünscht VOR der Rücksprungadresse. In der Prozedur selber müssen wir den SP auf das 3. Parameter zeigen lassen. Das geht per SUB SP, 6.
+------------------+ | leer | +------------------+ | 0x5678 | <- SP +------------------+ | 0x4321 | +------------------+ | 0x1234 | +------------------+ | Rücksprungadr. | +------------------+ | Null-Element | +------------------+
Per POP können wir nun unsere Parameter vom Stack herunter holen, ist dies geschehen zeigt der SP auf die Rücksprungadresse, und der RET Befehl kann korrekt ausgeführt werden.
+------------------+ | leer | +------------------+ | 0x5678 | +------------------+ | 0x4321 | +------------------+ | 0x1234 | +------------------+ | Rücksprungadr. | <- SP +------------------+ | Null-Element | +------------------+
Zu Beachten ist, das die Parameter natürlich Rückwerts ausgelesen werden müssen, da sie auf dem Stack gestapelt liegen.
main: sub sp, 3 ; Platz für Rücksprungadresse machen mov ba, 0x1234 ; Parameter 1 festlegen push ba ; Parameter 1 auf den Stack legen mov ba, 0x4321 ; Parameter 2 festlegen push ba ; Parameter 2 auf den Stack legen mov ba, 0x5678 ; Parameter 3 festlegen push ba ; Parameter 3 auf den Stack legen add sp, 9 ; SP vor den 3 Parametern plazieren für Rücksprungadresse mov ba, 0 ; BA auf 0 setzen, damit wir besser im Debugger sehen, was geschieht call prozedur ; Prozedur aufrufen jmp end ; Programm beenden prozedur: sub sp, 6 ; SP auf Parameter 3 zeigen pop ba ; Parameter 3 vom Stack holen pop ba ; Parameter 2 vom Stack holen pop ba ; Parameter 1 vom Stack holen ret ; SP zeigt auf Rücksprungadresse; Zurückkehren end: jmp end
Im Debugger können wir dann beim Ausführen der Prozedur sehen, das BA zuerst den Wert 0x5678 hat, dann 0x4321 und zum Schluss 0x1234.
Jetzt können wir uns eine Prozedur schreiben, die Spicher von einer Stelle zu anderen kopiert. Halten wir nochmal alle benötigten Parameter fest:
- Quelladresse: 24 Bit - Zieladresse: 24 Bit - Länge: 24 Bit
Die Länge ist die Anzahl der zu kopierenden Bytes. Wer ein bischen sich mit der WinAPI auskennt, der wird merken, das diese Prozedur wie die RtlMoveMemory Prozedur funktioniert. Das Kopieren erfolgt Byte für Byte. Dabei wird pro Byte die Quell- und Zieladresse um 1 erhöht, und die Länge um 1 verringert. Ist die Länge bei 0 angelangt, ist der Kopiervorgang beendet, und die Prozedur kann beendet werden.
kopiere: sub sp, 9 ; SP auf Parameter 3 zeigen pop hl ; Länge von Stack holen popx hl pop x2 ; Zieladresse von Stack holen pop a movx x2, a pop x1 ; Quelladresse von Stack holen pop a movx x1, a kopiere_schleife: mov a, [x1] ; kopiere Byte von Quelladresse in A mov [x2], a ; kopiere A in Zieladresse inc x1 ; erhöhe Quelladresse um 1 inc x2 ; erhöhe Zieladresse um 1 dec hl ; vermindere Länge um 1 cmp hl, 0 ; vergleiche Länge mit 0 jnz kopiere_schleife ; solange bis alle Bytes kopiert sind ret ; Parameter sind ausgelesen, SP zeigt auf Rücksprungadresse
Man kann sich hier jetzt auch noch eine Funktionen schreiben für 16 Bit Adressen, diese wäre dann schneller da das Herunternehmen der oberen 8 Bit von den 24 Bit Registern natürlich Zeit kostet.
Jetzt wollen wir uns noch anschauen, wie diese Prozedur aufgerufen wird:
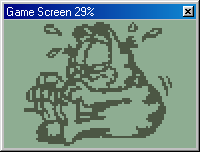
main: sub sp, 3 ; Platz für Rücksprungadresse machen mov hl, garfield ; Quelladresse pushx hl push hl mov hl, 0x001000 ; Zieladresse pushx hl push hl mov hl, 96*64/8 ; Länge hier 786 Byte pushx hl push hl add sp, 12 ; SP vor die 3 Parameter plazieren für Rücksprungadresse call kopiere ; Prozedur nun aufrufen ; lcd konfiguration 0 mov x1, 0x002080 mov [x1], 0b00001000 ; Enable 0 + Linearmodus ; lcd konfiguration 1 mov x1, 0x002081 mov [x1], 0b00001001 ; Enable 1 ; Programm beenden jmp end kopiere: sub sp, 9 ; SP auf Parameter 3 zeigen pop hl ; Länge von Stack holen popx hl pop x2 ; Zieladresse von Stack holen pop a movx x2, a pop x1 ; Quelladresse von Stack holen pop a movx x1, a kopiere_schleife: mov a, [x1] ; kopiere Byte von Quelladresse in A mov [x2], a ; kopiere A in Zieladresse inc x1 ; erhöhe Quelladresse um 1 inc x2 ; erhöhe Zieladresse um 1 dec hl ; vermindere Länge um 1 cmp hl, 0 ; vergleiche Länge mit 0 jnz kopiere_schleife ; solange bis alle Bytes kopiert sind ret ; Parameter sind ausgelesen, SP zeigt auf Rücksprungadresse garfield: .db 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00 .db 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x38, 0x6C, 0x6C, 0x4C .db 0x4C, 0x50, 0x70, 0xE0, 0xC0, 0x00, 0x00, 0x00, 0x00, 0x00, 0xC0, 0xF0 .db 0xF8, 0xF8, 0xF8, 0xFC, 0xEC, 0xCC, 0x98, 0xB8, 0xF8, 0xFC, 0x7E, 0xFE .db 0xFE, 0xFE, 0xFC, 0xFC, 0xDC, 0x30, 0xE0, 0xC0, 0x00, 0x00, 0x00, 0x00 .db 0x00, 0x00, 0x38, 0x2C, 0x22, 0x3C, 0x18, 0x00, 0x00, 0x00, 0x80, 0xC0 .db 0xC0, 0xA0, 0xB0, 0x90, 0xD0, 0x70, 0x70, 0x00, 0x00, 0x00, 0x00, 0x00 .db 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00 .db 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00 .db 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x80 .db 0xC0, 0xC0, 0xC0, 0xC0, 0x40, 0x00, 0xC0, 0xC0, 0xF0, 0xE0, 0xC0, 0xC1 .db 0xF7, 0x7F, 0x3D, 0x09, 0x84, 0xC6, 0x76, 0x3F, 0x0F, 0x0E, 0x06, 0x04 .db 0x0C, 0x0C, 0x09, 0x1B, 0xFF, 0xFE, 0x00, 0x03, 0x07, 0x3C, 0xF8, 0xF8 .db 0xF8, 0xFE, 0xFF, 0xBF, 0x3D, 0x34, 0x30, 0x00, 0x00, 0x07, 0x03, 0x01 .db 0x01, 0x01, 0x01, 0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00 .db 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00 .db 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00 .db 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x02, 0x07, 0x05 .db 0x06, 0x02, 0x01, 0x00, 0x00, 0x01, 0x01, 0x81, 0xFB, 0xFF, 0xE7, 0xFF .db 0x63, 0x40, 0xC0, 0xD0, 0xFF, 0xC7, 0x80, 0x80, 0xC0, 0xC0, 0x40, 0x40 .db 0x40, 0x60, 0xE0, 0xA0, 0xF6, 0xBF, 0x00, 0x00, 0x00, 0x00, 0x01, 0x01 .db 0xC1, 0xC1, 0xFF, 0xFF, 0xFE, 0xE0, 0x80, 0x00, 0x00, 0x00, 0x00, 0x00 .db 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00 .db 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00 .db 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00 .db 0x00, 0x00, 0x00, 0x00, 0xE0, 0xF0, 0x0C, 0x0C, 0xFC, 0x9C, 0x8C, 0x8C .db 0x8C, 0x8C, 0xDC, 0x30, 0x70, 0x40, 0x80, 0xDF, 0xFF, 0xF8, 0xFC, 0xEF .db 0x67, 0x66, 0x7F, 0xD9, 0x9F, 0x9F, 0x3F, 0x77, 0x67, 0x26, 0x36, 0x16 .db 0x0A, 0x1B, 0x1B, 0x91, 0x80, 0xE1, 0xC9, 0x7F, 0x1C, 0x00, 0x00, 0x00 .db 0xC0, 0xE0, 0xF0, 0xF1, 0xFF, 0xBF, 0x17, 0xF7, 0xFE, 0xFC, 0xF0, 0xC0 .db 0x00, 0x00, 0x00, 0x00, 0x00, 0x10, 0x30, 0xE0, 0x80, 0x10, 0xE0, 0x80 .db 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00 .db 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0xF0 .db 0xF8, 0x04, 0xFE, 0xFE, 0x87, 0x83, 0xFF, 0xEF, 0x87, 0x87, 0xFF, 0x3F .db 0x0F, 0xFF, 0xFC, 0x8C, 0xFC, 0x7E, 0xEF, 0xC7, 0xF1, 0xFD, 0x0D, 0x0D .db 0x86, 0x86, 0xC4, 0x00, 0x01, 0x03, 0x06, 0x0E, 0x0C, 0x0C, 0x08, 0x0C .db 0x0C, 0x1C, 0x1C, 0x0D, 0x0F, 0x0C, 0x0C, 0x0C, 0x0C, 0x0E, 0x0E, 0x84 .db 0x86, 0x87, 0x83, 0x03, 0x01, 0x01, 0x03, 0x03, 0x03, 0x01, 0x01, 0xC1 .db 0xEF, 0xFF, 0xFE, 0xFC, 0xF8, 0xF0, 0xC0, 0x01, 0x07, 0x3E, 0x00, 0x03 .db 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00 .db 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x30, 0x30 .db 0x31, 0x31, 0x31, 0x3F, 0x7F, 0x61, 0xEF, 0xFF, 0x31, 0x61, 0x81, 0x03 .db 0x16, 0xFF, 0xC7, 0x03, 0x7F, 0xC7, 0x86, 0x06, 0x01, 0x01, 0x03, 0x03 .db 0xFF, 0xFF, 0xC1, 0xC7, 0xCC, 0xCC, 0xC8, 0xCC, 0xFC, 0xFE, 0xFE, 0x3E .db 0x3E, 0x3E, 0x1E, 0x0F, 0x0F, 0x07, 0x07, 0x07, 0x07, 0x03, 0x03, 0x01 .db 0x03, 0x03, 0x03, 0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x01, 0x03, 0x03 .db 0x87, 0x83, 0xC3, 0xC3, 0xE1, 0xFB, 0xFF, 0xFE, 0x78, 0x00, 0x00, 0x00 .db 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00 .db 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00 .db 0x00, 0x00, 0x00, 0x00, 0x80, 0xE0, 0xF0, 0xFB, 0xFE, 0xDC, 0x0D, 0x0C .db 0x0C, 0x04, 0x07, 0x0F, 0xFE, 0xFC, 0x1F, 0x1E, 0x00, 0x00, 0x00, 0x04 .db 0x0F, 0x0F, 0x0E, 0x86, 0x86, 0x86, 0x86, 0xC3, 0xC3, 0xC3, 0xC3, 0xC3 .db 0xC3, 0xC3, 0xC1, 0xC0, 0xC0, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00 .db 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x60, 0xC0, 0xC0, 0xC0, 0xC0, 0xE2 .db 0xC7, 0xE7, 0xFF, 0xFF, 0x3F, 0x1F, 0x0F, 0x03, 0x00, 0x00, 0x00, 0x00 .db 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00 .db 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00 .db 0x00, 0x00, 0x00, 0x00, 0x09, 0x1F, 0x1F, 0x1F, 0x1F, 0x1F, 0x3C, 0x3E .db 0x3C, 0x3C, 0x3E, 0x3E, 0x3F, 0x3F, 0x78, 0x60, 0x60, 0x20, 0x38, 0x1C .db 0x0E, 0x0F, 0x0F, 0x07, 0x07, 0x07, 0x07, 0x07, 0x07, 0x07, 0x07, 0x07 .db 0x03, 0x07, 0x07, 0x06, 0x06, 0x06, 0x04, 0x04, 0x04, 0x04, 0x04, 0x04 .db 0x04, 0x04, 0x04, 0x04, 0x06, 0x06, 0x06, 0x07, 0x07, 0x07, 0x07, 0x03 .db 0x03, 0x01, 0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00 .db 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00 end: jmp end
Obwohl die Hardware eigentlich in Tutorial 2 beschrieben werden soll, habe ich hier mal ein praktisches Beispiel vorgegriffen, wo Garfield(der dicke Kater, der so viel Lasagne isst) auf dem Bildschirm ausgegeben wird :)
Rückgabewerte
Wenn eine Prozedur eine mathematische Gleichung ausrechnen, oder über Erfolg bzw. Misserfolg berichten soll, dann kommen Rückgabewerte ins Spiel. Diese lassen sich auch wieder auf den Stack legen, oder als Register übergeben. Hier macht aber es recht wenig Sinn über den Stack zu gehen, da eine Prozedur fast ausschließlich nur ein Rückgabewert besitzt, und auch mehrere Rückgabewerte in mehrere Register geschrieben werden können. Die Methode über Register ist sowieso immer schneller. Als Beispiel schreiben wir uns eine Prozedur die Register A mit 3 multipliziert und das Ergebnis in B auslagert.
main: mov a, 10 ; A = 10 call mul3 ; B = 10*3 = 30 jmp end mul3: mov b, a ; A in B sichern sal a ; A = A*2; auch das Vorzeichen wird beachtet adc a, b ; A = A+B mov b, a ; B = A; unser Rückgabewert ret end: jmp end
Das Auslagern in B ist zwar nicht nötig, soll aber zeigen das hier B als Rückgabewert extra behandelt wird. Wie zu sehen ist, wird auch das Rückgaberegister in der Prozedur benötigt, es kommt jedoch nur darauf an, das am Ende bevor RET ausgeführt wird, in B das richtige Ergebnis steht.
Assembler Direktiven
Als Assemblerprogrammierer hat man es nicht besonders leicht, deswegen stellen die meisten Assembler sogeannte Direktiven zur Verfügung, die das Programmieren mit ihm um einiges erleichtern. Eine Direktive ist eine Verhaltensanordnung von höherer Stelle. Wir als Programmierer stellen praktisch diese höhere Stelle dar. Direktiven sind leicht an dem Punkt vor den Direktivenname zu erkennen. Die Direktiven .orgfill und .end haben wird ja bereits schon eingesetzt. Hier die wichtigsten Direktiven:
.include
Include steht für Einfügen. Bei größeren Projekten ist es oft hilfreich den Quellcode in kleinere Quellcodes aufzuteilen. In so einer Includedatei kann z. B. das Framework stehen, Prozeduren, Definitionen usw.. Diese Includedatei darf jedoch auch nur reinen Assemblercode enthalten. Der Assembler ersetzt dann die Direktive durch den Inhalt der Includedatei.
Framework.asm:
.orgfill 0x0009A jmp main .orgfill 0x02100 .db "MN" .orgfill 0x021A4 .db "NINTENDO" ; Groß- und Kleinschreibung beachten! .db "Code" ; Spielecode .db "Titel" ; Titel darf maxmimal 12 Zeichen groß sein .orgfill 0x021BC .db "2P" .orgfill 0x021D0
.include "Framework.asm" main: movb a, 1 ; kopiere 1 in Register A addb a, 2 ; addiere 2 hinzu end: jmp end
Man kann sich hier besser um den eigentlichen Quellcode kümmern.
.equ
Equ steht für Equal - gleichbedeutend. Man definiert einen Namen mit einem dazugehörigen Wert, und der Name wird dann im gesamten Quellcode durch den dazugehörigen Wert ersetzt. Man darf sich das ganze vorstellen wie eine symbolische Konstante in höheren Sprachen.
.equ KEYPAD 0x002052 ; Adresse des Keypads ist 0x002052 main: mov a, [KEYPAD] ; A = [0x002052] ; ist das selbe wie mov a, [0x002052] end: jmp end
.org
Org steht für Origion also Ursprung. Dabei wird der Ursprungort für den folgenden Code an die festgelegte Adresse positioniert.
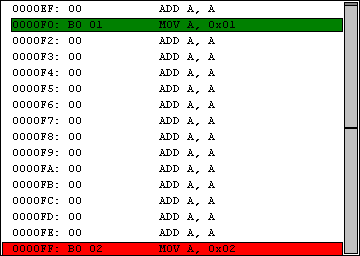
.org 0x0000F0 ; dieser Code steht an Position 0x0000F0 im RAM mov a, 0x01 .org 0x0000FF ; dieser Code steht an Position 0x0000FF im RAM mov a, 0x02
Würde man sich nun die assembelierte Datei im Debugger anschauhen, und zu Adresse 0x0000F0 springen, könnte man den Ausdruck MOV A, 0x01 sehen.
.orgfill
Diese Direktive ist änlich wie .org jedoch wie man an dem "fill" erkennen kann, wird das Übersprungene durch Nullen gefüllt. Wichtig ist das z. B. in unseren Framework, da der PM auch schaut, ob wirklich die 0en vorhanden sind.
.orgfill 0x0009A jmp main .orgfill 0x02100 .db "MN" .orgfill 0x021A4 .db "NINTENDO" ; Groß- und Kleinschreibung beachten! .db "Code" ; Spielecode .db "Titel" ; Titel darf maxmimal 12 Zeichen groß sein .orgfill 0x021BC .db "2P" .orgfill 0x021D0
.end
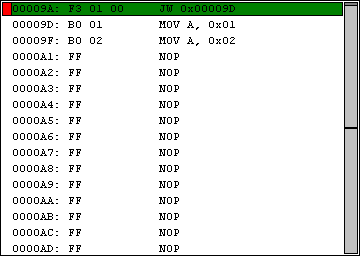
End zu deutsch Ende weist darauf hin, das alles was nach dieser Direktive kommt, vom Assembler ignoriert werden kann.
.org 0x00009A jmp main main: ; wird assembeliert mov a, 0x01 mov a, 0x02 .end ; wird nicht mit assembeliert mov a, 0x03
.incbin
IncBin steht für Include Binary - Einbinden einer binären Datei. Der Assembler ersetzt die Direktive durch den Inhalt der Datei. Im Gegensatz zu .include wird hier kein Quellcode übersetzt. Jede beliebige Datei kann somit hier eingesetzt werden. Man kennzeichnet am besten eine Resource durch ein Label.
bild: incbin "Bild.bin"
.macro
Macro zu deutsch Makro ist eine Abkürzung für häufig verwendete Codeabschnitte. Man definiert einmal eine Anweisung im Quellcode, und der Assembler ersetzt jedesmal den Namen des Makros durch diese Anweisung. Prozeduren lassen sich dadurch wesentlich leichter gestalten, vorallem weil man auch Übergabeparameter leicht definieren kann. Dabei ist jedoch zu beachten, das Prozeduren nur einmal in der assembelierten Datei vorkommen, Makros jedoch immer durch ihren Inhalt ersetzt werden. Man kennzeichnet das Ende eines Makros mit der Direktive .endm was für End Macro steht.
.macro kopiere16 quelladresse, zieladresse, laenge mov x1, quelladresse mov x2, zieladresse mov hl, laenge kopiere16_schleife: mov a, [x1] mov [x2], a inc x1 inc x2 dec hl cmp hl, 0 jnz kopiere16_schleife .endm main: ; einfacher Makroaufrauf kopiere16 garfield, 0x001000, 786 mov x1, 0x002080 mov [x1], 0b00001000 mov x1, 0x002081 mov [x1], 0b00001001 jmp end
In dem Beispiel gibt es ein Makro, das mit 16 Bit Adressen und einer 16 Bit Länge arbeitet. Der Aufruf erfolgt wesentlich übersichtlicher und einfacher als alles über den Stack zu regeln.
Wer dennoch mit Prozeduren arbeiten möchte, aus Platzgründen z. B., kann sich zumindest den Aufruf einer Prozedur wesentlich erleichtern. Praktisch dabei ist, das der Assembler beim Namen unterscheiden kann, ob man hier ein Makro oder ein Label benutzt. Somit darf man den Namen der Prozedur auch für das Makro verwenden.
.macro prozedur para1, para2, para3 sub sp, 3 mov ba, para1 push ba ; Parameter 1 auf den Stack legen mov ba, para2 push ba ; Parameter 2 auf den Stack legen mov ba, para3 push ba ; Parameter 3 auf den Stack legen add sp, 9 ; SP vor den 3 Parametern plazieren für Rücksprungadresse mov ba, 0 ; BA auf 0 setzen, damit wir besser im Debugger sehen, was geschieht call prozedur ; Prozedur aufrufen .endm main: prozedur 1, 2, 3 ; Prozedur per Makro aufrufen jmp end ; Programm beenden prozedur: sub sp, 6 ; SP auf Parameter 3 zeigen pop ba ; Parameter 3 vom Stack holen pop ba ; Parameter 2 vom Stack holen pop ba ; Parameter 1 vom Stack holen ret ; SP zeigt auf Rücksprungadresse; Zurückkehren end: jmp end
Abschließende Worte
Ich hoffe, mir ist es gelungen das Grundlegende Verständnis von Assembler und dem Einsatz im PM rüber zu bringen, auch für die Leute, die bisher nichts mit Programmieren am Hut hatten.
Programmieren lernt man durch Programmieren! Wer also komplett neu auf dem Gebiet ist, für den heißt es ausprobieren ohne Ende.
Im nächsten Tutorial wird es dann hauptsächlich um Praxisanwendungen also um Hardwareprogrammierung gehen. Wann und ob das nächste Tutorial erscheinen wird, das lass ich mir als Autor offen.
Mein Danksagung geht vorallem an goldmomo und Tharo, sowie an camper und wasiliy. Natürlich auch an das komplette PokeMe Team, ohne die es dieses Tutorial garnicht geben würde.
mfg olli